“정답이 없는 주식 분류 문제, 왜 클러스터링을 선택했을까?”
지난 글에서 이야기했듯이,
주식쌤의 목표는 사용자의 투자 성향을 분석하는 것이었습니다.
처음 떠올린 가장 단순한 기준: 코스피 vs 코스닥
처음에는 가장 직관적인 분류 기준을 떠올렸습니다.
- 코스피 → 대형 우량주, 안정적인 기업
- 코스닥 → 성장주, 고위험·고수익 기업
하지만 코스피에는 삼성전자 같은 대형 우량주도 많지만 실적이 지속적으로 악화된 기업 , 상장폐지 직전의 관리 종목도 함께 존재합니다.
반대로 코스닥에는 단기 테마성 종목도 많지만 시가총액이 크고, 기술력과 매출을 갖춘 거대 성장주도 분명히 존재합니다.
즉,
“코스피니까 우량주다”
“코스닥이니까 위험하다”
라는 기준은 AI에게 학습시키기에는 너무 거칠고 부정확한 라벨이었습니다.
이 상태로 학습을 시키면 AI는 잘못된 정답을 정답으로 배우게 됩니다.
그래서 다시 질문했다 : 우량주는 도대체 무엇인가?
이 지점에서 저는 방향을 바꿔 주식을 직접 공부하기 시작했습니다.
증권사 리포트와 여러 자료를 살펴보니, ‘우량주’라는 단어는 명확한 공식 정의는 없지만
공통적으로 다음 세 가지 기준이 반복해서 등장했습니다.
우량주를 구성하는 3대 요소
- 규모 (Size)
- 시가총액이 충분히 큰가?
- 수익성 (Profitability)
- 돈을 꾸준히, 잘 버는가?
- 대표 지표: ROE
- 안정성 (Stability)
- 빚이 과도하지 않고 재무 구조가 탄탄한가?
- 대표 지표: 부채비율
하지만 여기서도 또 하나의 문제가 있었습니다.
- ROE 14%는 부족하고 15%부터 우량주일까?
- 부채비율 110%는 위험하고 99%는 안전할까?
이 질문에는 명확한 정답이 존재하지 않았습니다.
이건 사람이 기준을 정할 문제가 아니었다
이 순간 깨달았습니다.
주식 분류는 사람이 if문으로 기준을 정하는 순간 주관적인 룰 기반 시스템이 되어버린다는 것을요.
if 시가총액 상위 100위 and ROE > 15%:
우량주이 방식은 빠르게 구현할 수는 있지만,
- 기준은 사람이 정하고
- 기준선은 애매하며
- 주식 수가 늘어날수록 관리가 불가능해집니다.
제가 만들고 싶었던 것은
대규모 하드코딩 시스템이 아니라 AI 모델이었습니다.
그래서 선택한 방식: 클러스터링
여기서 선택한 접근이
비지도 학습(Unsupervised Learning) 기반의 클러스터링(Clustering) 이었습니다.
간단하게 클러스터링이란 무엇인지 알아보겠습니다.
클러스터링이란 유사한 특성을 가진 데이터 포인트를 군집화 시켜묶는 머신러닝의 비지도 학습 방법 입니다.
말이 너무 어렵죠? 다음 예시를 한번 보시죠
 |
 |
 |
 |
 |
 |
 |
 |
 |
대한민국 프랑스 브라질
독일 미국 일본
이탈리아 칠레 캐나다
9개의 나라가 있습니다. 이 나라들은 1인당 GDP, 인구수, 기후 등 어떤 기준으로든 분류 할 수가 있습니다.
왜 가능할까요? → 정답이 없기 때문입니다.
그리고 K-means알고리즘으로 클러스터링(군집화)해 보면 다음과 같은 결과가 나올 수 있습니다.
[그룹1]
대한민국, 일본
[그룹2]
독일, 프랑스, 이탈리아
[그룹3]
브라질, 칠레
[그룹4]
캐나다, 미국
이렇게 분류 될 것입니다. 이들은 거리 기반으로 군집화 되었습니다.
K-means알고리즘은 중심점 사이의 거리를 계산하여 가장 가까운 중심에 데이터를 배정하는 알고리즘이기 때문입니다.
여기서 K는 4, 즉 그룹의 개수입니다.
이 접근을 스톡잇!에 적용한다면?
이처럼 클러스터링을 스톡잇!에 적용한다면 어떻게 될까요?
“삼성전자는 우량주다”라고 AI에게 알려주는 것이 아니라,
재료만 주고 분류는 AI에게 맡기자.
라는 결론에 도달했습니다.
이때 재료들은 어떤 재료일까요?
한국투자증권 API에서 제공하는 다음 지표들을 사용했습니다.
- 시가총액: 기업의 전체 시장 규모를 나타내는 지표입니다.
- PER: 기업의 이익 대비 주가가 얼마나 비싼지를 나타내는 지표입니다.
- PBR: 기업의 자산 가치 대비 주가 수준을 나타내는 지표입니다.
- ROE: 자기자본으로 얼마나 효율적으로 이익을 내는지를 나타내는 지표입니다.
- 부채비율: 자기자본 대비 부채 수준으로 재무 안정성을 나타내는 지표입니다.
- 배당수익률: 주가 대비 배당금으로 얻을 수 있는 수익 비율을 나타내는 지표입니다.
자세한 용어정리
1. 시가총액 (Market Capitalization)
시가총액은 해당 기업의 시장 규모를 나타내는 지표입니다.
시가총액 = 주가 × 발행 주식 수
기업이 시장에서 얼마나 큰 회사인지 대형주 / 중형주 / 소형주를 구분할 때 사용
일반적으로,
시가총액이 클수록 기업의 사업 규모가 크고 시장에서 차지하는 영향력이 큼 변동성이 상대적으로 낮은 경향이 있습니다.
👉 우량주 판단에서 ‘규모(Size)’를 대표하는 지표입니다.
2. PER (주가수익비율, Price Earnings Ratio)
PER은 기업의 이익 대비 주가가 얼마나 비싼지를 나타냅니다.
PER = 주가 ÷ 주당순이익(EPS)
PER이 낮다 → 이익 대비 주가가 낮다 (저평가 가능성) PER이 높다 → 성장 기대가 크거나, 고평가 가능성
다만,
적자 기업의 경우 PER이 음수이거나 계산 불가 산업군마다 적정 PER 수준이 다름
👉 가치주 / 성장주 구분에 중요한 지표입니다.
3. PBR (주가순자산비율, Price Book-value Ratio)
PBR은 기업의 자산 대비 주가 수준을 나타냅니다.
PBR = 주가 ÷ 주당순자산(BPS)
PBR < 1 → 이론적으로는 자산 가치보다 낮게 거래 중 PBR > 1 → 자산 가치 이상으로 평가받고 있음
전통적인 가치투자에서는 PBR이 낮은 기업을 저평가 기업으로 보는 경우가 많습니다.
👉 가치주 판단의 핵심 지표 중 하나입니다.
4. ROE (자기자본이익률, Return On Equity)
ROE는 기업이 자기자본으로 얼마나 효율적으로 돈을 벌고 있는지를 나타냅니다.
ROE = 순이익 ÷ 자기자본 × 100
ROE가 높다 → 자본을 잘 활용해 이익을 내고 있음 ROE가 낮다 → 자본 대비 수익성이 떨어짐
일반적으로,
ROE 15% 이상 → 수익성이 좋은 기업으로 평가되는 경우가 많습니다.
👉 우량주 판단에서 ‘수익성(Profitability)’을 대표하는 지표입니다.
5. 부채비율 (Debt Ratio)
부채비율은 기업의 재무 안정성을 보여주는 지표입니다.
부채비율 = 부채 ÷ 자기자본 × 100
부채비율이 낮다 → 재무 구조가 안정적 부채비율이 높다 → 외부 차입에 대한 의존도가 큼
산업 특성에 따라 다르지만,
일반적으로 100% 이하를 안정적으로 보는 경우가 많습니다.
👉 우량주 판단에서 ‘안정성(Stability)’을 대표하는 지표입니다.
6. 배당수익률 (Dividend Yield)
배당수익률은 주식을 보유했을 때 배당금으로 얼마나 수익을 얻을 수 있는지를 나타냅니다.
배당수익률 = 주당 배당금 ÷ 주가 × 100
배당수익률이 높다 → 안정적인 현금 흐름 장기 투자자, 안정형 투자자가 선호
배당을 꾸준히 지급하는 기업은 대체로 실적과 재무 구조가 안정적인 경우가 많습니다.
👉 배당주 성향을 판단하는 핵심 지표입니다.
왜 이 지표들을 AI에게 줬는가
중요한 점은,
이 지표들 자체로 “이 주식은 우량주다” 라고 판단하지 않았다는 것입니다.
우리는 AI에게 이렇게 말했습니다.
“이 지표들을 보고,
네가 보기엔 비슷한 주식들끼리 묶어봐.”
즉,
- 사람은 기준을 정하지 않고
- AI는 숫자의 분포와 유사도를 기반으로
- 주식들을 자연스럽게 군집화합니다.
데이터 수집 과정
데이터는 한국투자증권 API를 사용해 수집했습니다.
① 종목 리스트 확보
df_master = get_stock_code_list()
stock_codes = df_master["단축코드"].tolist()전체 종목을 한 번에 확보해 반복 호출의 기준으로 사용했습니다.
② 종목별 지표 수집 (Rate Limit 고려)
for code in stock_codes:
price = get_price_info(code)
time.sleep(1.0)
finance = get_finance_ratios(code)
time.sleep(1.0)
dividend = get_dividend_rate(code)③ 데이터 병합 및 저장
final_df = pd.merge(df_master, df_api_data, on="단축코드")
final_df.to_csv(...)모든 지표를 하나의 피처 테이블로 통합했습니다.
수집 결과
총 3619개의 데이터를 수집했습니다.

3619개의 데이터에는 6개의 핵심 지표로 구성된 데이터셋을 확보했습니다.
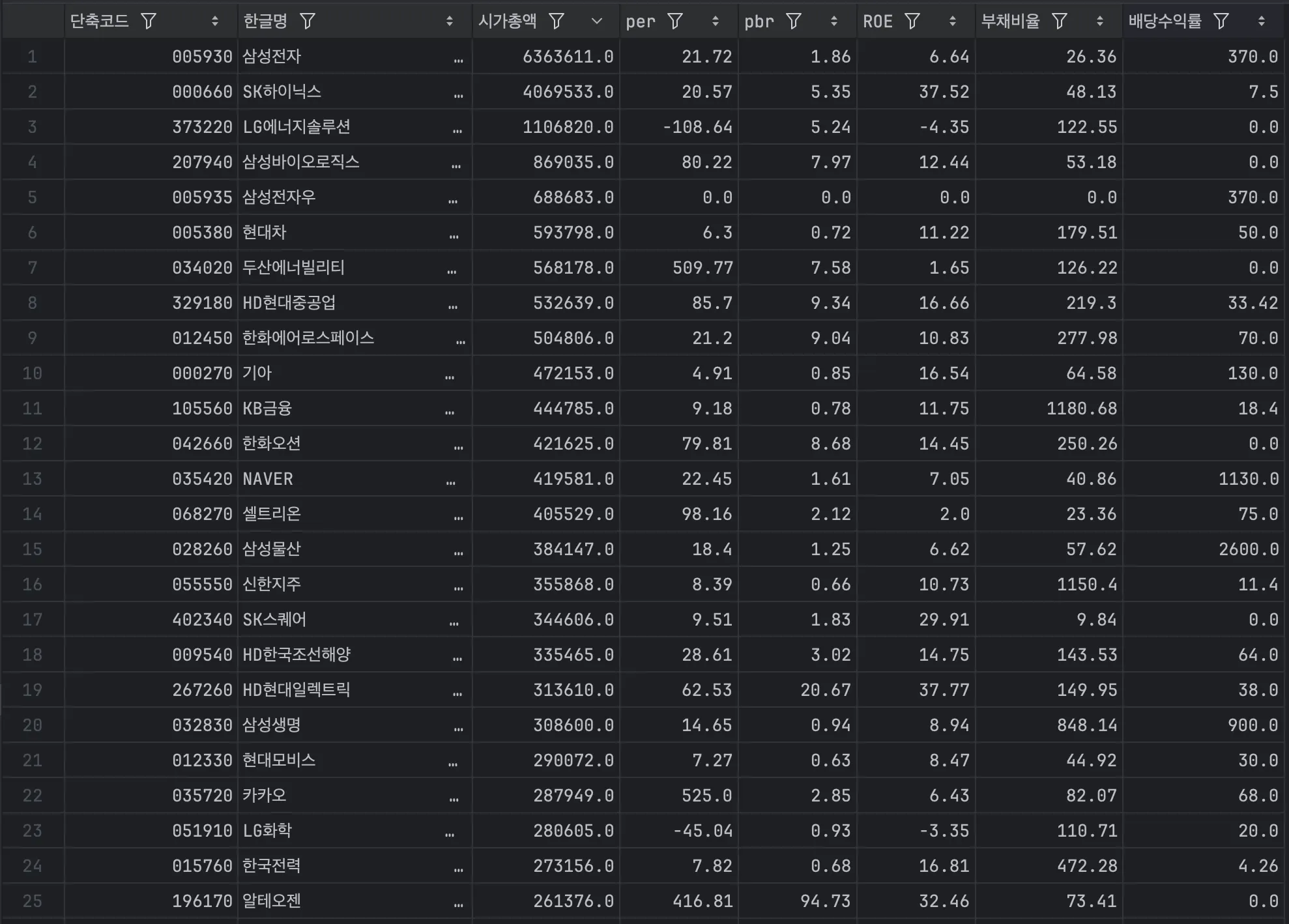


다음 글에서는 이 데이터들을 그대로 쓰지 않고, "학습에 적합한 형태로 변환 하는 전처리 과정"에 대해 다뤄보겠습니다.
'모의투자' 카테고리의 다른 글
| ~숫자를 언어로 번역하다 : 태깅~ 스톡잇! 개발기 #5 (1) | 2025.12.26 |
|---|---|
| ~숫자만 보고 주식을 나누다: K-means 클러스터링 과정~ 스톡잇! 개발기 #4 (0) | 2025.12.25 |
| ~학습에 적합한 형태로 변환하다 : 전처리 과정~ 스톡잇! 개발기 #3 (0) | 2025.12.18 |
| ~3,619개의 주식, if문(Rule-Base)으로 분류할 수 있을까?~ 스톡잇! 개발기 #1 (1) | 2025.12.17 |
| ~Prologue: 투기가 아닌 투자의 길~ 스톡잇! 개발기#0 (1) | 2025.12.11 |