" 성향을 캐릭터로 만들다: 페르소나 매칭 설계"
지난 글에서 저는 AI가 만든 숫자를 사람이 이해할 수 있는 언어로 바꾸는 작업을 했습니다.
하지만 단순히 정보를 전달하는 것만으로는 충분하지 않았습니다.
사용자가 결과를 읽는 것이 아니라,
“아, 이게 나구나”라고 스스로를 이해하게 만드는 단계가 필요했기 때문입니다.
그래서 바로 사람의 언어로 된 투자 성향 ‘페르소나(Persona)’가 필요했습니다.
이번 글에서는 정답 데이터가 전혀 없는 상황에서
어떻게 페르소나 매칭 시스템을 설계했는지에 대해 이야기해보려 합니다.
문제 : 워렌 버핏은 삼성전자를 안 샀는데?
사용자에게 단순히 "당신은 가치주 성향입니다"라고 말하는 것보다,
"당신은 워렌 버핏과 비슷하네요!"라고 말해주는 것이 훨씬 직관적이고 이해하기 쉽습니다.
하지만 여기서 치명적인 논리적 오류에 부딪혔습니다. 1편에서 이미 언급했던 그 문제입니다
문제상황
- 워렌 버핏, 피터 린치 같은 거장들은 미국 주식 위주로 투자했다.
- Stockit은 한국 주식을 분석한다.
- "삼성전자를 샀으니 버핏 스타일이다"라고 AI를 학습시킬 근거 데이터가 없다.
'워렌 버핏 스타일의 한국 주식'이라는 정답지가 세상에 존재하지 않았습니다.
즉, 정답 데이터가 없는 상황입니다.
데이터가 없으니 AI 학습도 불가능한 상황이었습니다.
그렇다고 룰 베이스(Rule-Based) 엔진을 도입하는 것은 망설여졌습니다.
사람이 일일이 규칙을 정하는 방식은, 데이터 속에서 스스로 패턴을 찾아내는 머신러닝의 핵심 가치를 포기하는 것과 다름없었기 때문입니다. 또한, 제가 임의로 정한 규칙이 정확하다고 확신할 수도 없었습니다.
가설 : 합의점을 찾다
이 과정에서 저는 한 가지 가설을 세웠습니다.
"머신러닝의 '분류' 능력과 인간의 '해석' 능력을 결합한 하이브리드 방식을 도입하면 어떨까?"
AI는 방대한 데이터를 처리해 주식들을 성향별로 묶는(Clustering) 역할만 수행하고, 그 묶음이 어떤 의미인지 정의(Definition)하는 것은 도메인 지식을 가진 인간이 맡는 구조라면, 정답 데이터(Label)가 없더라도 논리적인 시스템을 구축할 수 있을 것이라 판단했습니다.
해결방법 : AI가 분류하고 인간이 정의하는 하이브리드 구조
가설을 바탕으로 Stockit의 포트폴리오 분석 시스템을 다음과 같이 완성했습니다.
1️⃣ AI의 역할: 객관적 분류
K-Means 알고리즘이 한국 주식 시장의 데이터를 분석해 8개의 성향 그룹으로 분류합니다.
이 과정에는 인간의 편견이 개입되지 않습니다.
오직 숫자의 유사성만 존재합니다.
2️⃣ 인간의 역할: 의미 부여
저는 위키피디아, 자서전, 인터뷰 자료를 기반으로 각 투자 거장의 철학을 재무 지표 단위로 분해했습니다.
그리고 AI가 만든 8개의 그룹과 투자 거장 페르소나를 1:1로 직접 매칭했습니다.
벤저민 그레이엄 (안전마진 중시) -> PBR과 부채비율이 가장 낮은 [6번: 초저평가 가치주] 그룹과 매칭
워렌 버핏 (해자, 효율 중시) -> ROE가 가장 높은 [1번: 고효율 우량주] 그룹과 매칭
피터 린치 (성장+가치, GARP) -> 적당한 PBR에 성장성이 있는 [7번: 고가치 성장주] 그룹과 매칭

3️⃣ 사용자 포트폴리오 → 페르소나 매칭
이제 AI가 만든 성향 그룹을 실제 사용자 포트폴리오에 적용할 차례입니다.
사용자가 보유한 주식을 분석하면,
- 각 종목이 어느 그룹에 속하는지 계산되고
- 투자 금액을 기준으로
- 그룹별 비중 벡터가 만들어집니다
즉, 사용자의 투자 성향은 감각적인 설명이 아니라 숫자로 된 벡터로 표현됩니다.
1️⃣ 사용자 투자 성향을 벡터로 만들기
먼저 사용자의 포트폴리오를 준비합니다.
user_portfolio_data = {
'단축코드': ['10690', '44450', '79940'],
'투자금액': [1000000, 1000000, 1000000]
}
user_df = pd.DataFrame(user_portfolio_data)각 종목은 이미 앞선 단계에서
AI가 분류한 K-Means 그룹 번호(group_tag)를 가지고 있습니다.
이제 이 정보를 합쳐
“사용자가 어떤 성향의 주식에 얼마나 투자했는지”를 계산합니다.
merged_df = pd.merge(user_portfolio_df, df_tags, on='단축코드', how='left')
merged_df['비중'] = merged_df['투자금액'] / merged_df['투자금액'].sum()
user_style_raw = merged_df.groupby('group_tag')['비중'].sum()그리고 K-Means에서 정의한
0~7번 모든 그룹이 포함되도록 벡터를 완성합니다.
all_groups = np.arange(8)
user_style_vector = user_style_raw.reindex(all_groups, fill_value=0.0).values
user_style_vector = user_style_vector / user_style_vector.sum()이 결과는 다음과 같은 의미를 가집니다.
사용자의 투자 성향 = 8차원 공간 위의 하나의 점
각 차원은 하나의 투자 성향 그룹이며,
값은 해당 성향에 투자한 비중입니다.
2️⃣ 페르소나는 “순수 벡터”다
페르소나는 조금 다릅니다.
워렌 버핏, 벤저민 그레이엄 같은 투자 거장은
혼합 성향이 아니라 명확한 철학의 기준점입니다.
그래서 페르소나는 이렇게 정의됩니다.
# 워렌 버핏: 고효율 우량주 100%
BUFFETT = {1: 1.0}
# 벤저민 그레이엄: 초저평가 가치주 100%
GRAHAM = {6: 1.0}이건 수학적으로 보면
[0, 1, 0, 0, 0, 0, 0, 0]
처럼 특정 성향만 100%인 ‘순수 벡터(Prototype)’입니다.
즉,
- 사용자 → 혼합 벡터
- 페르소나 → 기준 벡터
이제 남은 질문은 단 하나입니다.
3️⃣ “얼마나 비슷한가?”를 어떻게 계산할까
두 벡터가 주어졌을 때,
“사용자의 투자 성향이
이 페르소나와 얼마나 가까운가?”
이 질문은 자연스럽게 이렇게 바뀝니다.
8차원 공간에서
두 점 사이의 거리는 얼마인가?
그래서 Stockit에서는
유클리디안 거리(Euclidean Distance)를 사용했습니다.
from numpy.linalg import norm
distance = norm(user_vector - persona_vector)이 선택은 임의가 아닙니다.
- 사용자 성향과 페르소나는 모두 벡터
- K-Means 자체가 유클리디안 공간을 전제로 동작
- 거리 개념이 직관적이고 설명 가능
즉, 처음부터 끝까지 하나의 수학적 세계관 안에 있습니다.
4️⃣ 거리 → 사람이 이해할 수 있는 ‘유사도’
거리만으로는 사용자에게 설명하기 어렵습니다.
그래서 이를
백분율 유사도로 변환했습니다.
max_distance = np.sqrt(2.0)
similarity = 100 - (distance / max_distance * 100)그 결과,
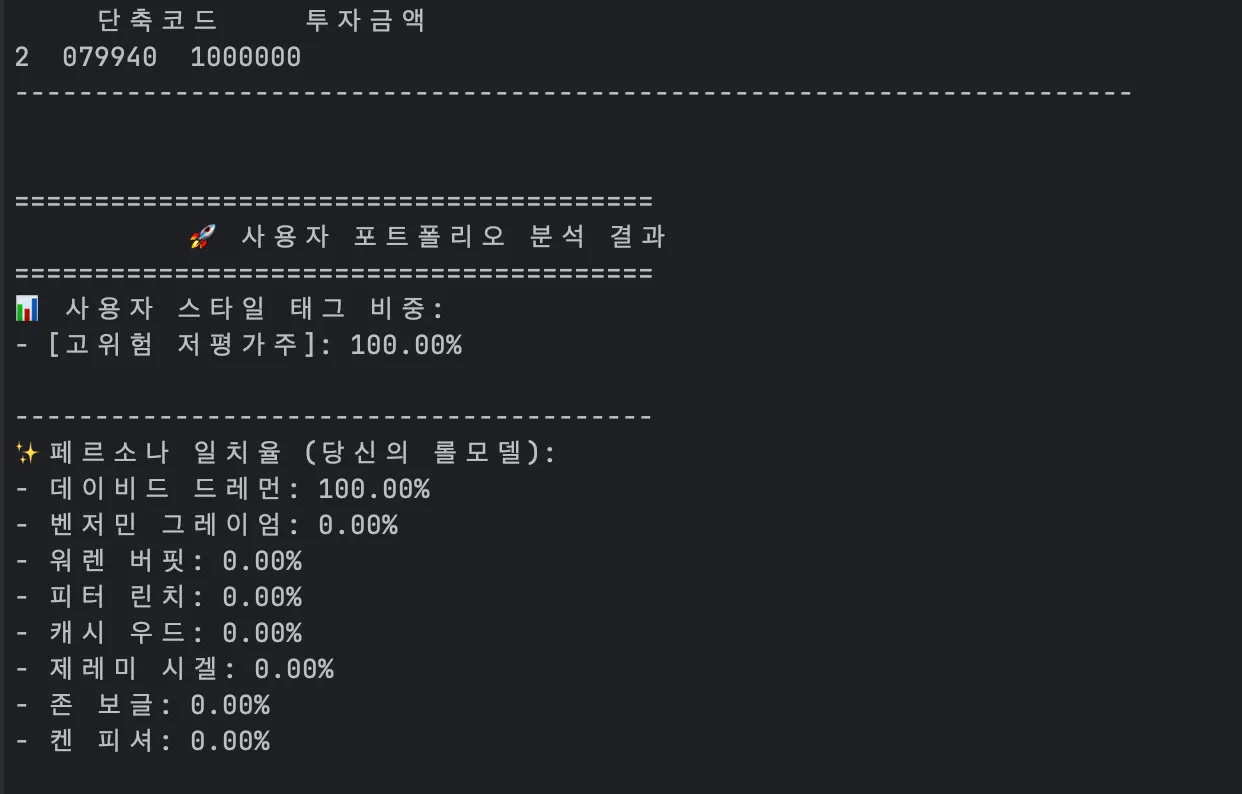
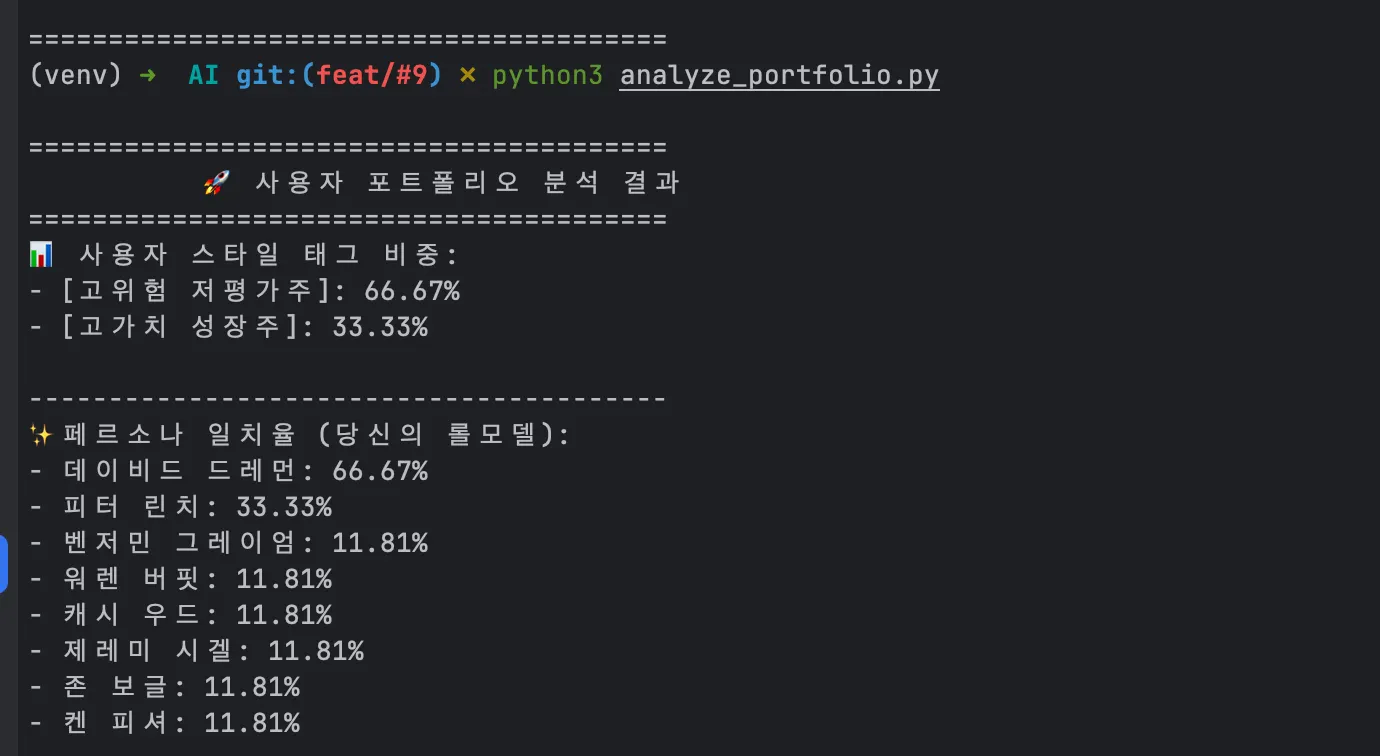
이 숫자는 감각적인 점수가 아닙니다.
- 사용자의 실제 포트폴리오
- AI가 만든 성향 벡터
- 페르소나 기준 벡터
- 거리 계산
이 모든 과정을 거쳐 나온
논리적 결과입니다.
스타일 태그를 넘어, 페르소나 매칭까지
이 구조 덕분에 Stockit은 정답 데이터가 없는 문제에서 “논리적으로 납득 가능한 결과”를 만들 수 있었습니다.
기술적으로는 비지도 학습(Unsupervised Learning)과 룰 베이스(Rule-Based) 로직의 결합.
이 구조가 바로 정답 데이터가 없는 난제를 논리적으로 해결한 Stockit만의 솔루션입니다.
지금까지의 모든 과정은 학습에 사용된 500개의 정제된 데이터셋 안에 있는 주식들을 분석하는 과정을 다뤘습니다.
하지만 여기에는 분명한 한계가 있습니다.
지금까지의 방식은 이미 학습된 목록에 존재하는 주식만 분석할 수 있는 조회(Lookup) 방식이라는 점입니다.
그렇다면 이런 질문이 자연스럽게 떠오릅니다.
만약 학습 데이터에 없었던 극단치중 하나인 삼성전자가 들어오면 어떻게 될까?
지금까지의 시스템은 이 질문에 답할 수 없었습니다.
이제부터는 500개의 데이터셋으로 학습을 마친 AI 모델(K-Means)을 사용해,
주식을 실시간으로 분석할 수 있는 ‘예측 엔진’을 구현해야 합니다.
드디어, 갇혀 있던 주식쌤을 세상 밖으로 꺼낼 시간입니다.

다음 글에서는 "세상의 모든 주식을 분석하다 : 조회에서 예측으로"에 대해 다뤄보겠습니다.
'모의투자' 카테고리의 다른 글
| ~파이썬 AI, 웹 서버가 되다 : MSA와 FastAPI 아키텍처에 대한 고찰~ 스톡잇! 개발기 #8 (0) | 2025.12.26 |
|---|---|
| ~세상의 모든 주식을 분석하다 : 조회에서 예측으로~ 스톡잇! 개발기 #7 (0) | 2025.12.26 |
| ~숫자를 언어로 번역하다 : 태깅~ 스톡잇! 개발기 #5 (1) | 2025.12.26 |
| ~숫자만 보고 주식을 나누다: K-means 클러스터링 과정~ 스톡잇! 개발기 #4 (0) | 2025.12.25 |
| ~학습에 적합한 형태로 변환하다 : 전처리 과정~ 스톡잇! 개발기 #3 (0) | 2025.12.18 |