"세상의 모든 주식을 분석하다 : 조회에서 예측으로"
지난 글에서 저는 500개의 정제된 데이터셋을 분석하고, 각 그룹에 페르소나를 부여했습니다.
하지만 이 시스템에는 치명적인 한계가 있었습니다.
바로 조회(Lookup) 방식이라는 점입니다.
우리가 만든 시스템은 500개의 명단을 가지고 있습니다.
만약 사용자가 명단에 있는 주식을 가져오면 "아, 그거 3번 그룹이네요"라고 대답합니다.
하지만 명단에 없는, 예를 들어 학습에 포함되지 않은 삼성전자를 가져오면 어떻게 될까요?
"모르는 주식입니다."
이것은 진정한 인공지능이 아닙니다. 진정한 AI라면 배우지 않은 주식을 마주쳐도, 자신이 학습한 기준(모델)을 바탕으로 스스로 판단할 수 있어야 합니다.
이번 글에서는 500개의 데이터셋으로 학습을 마친 AI 모델(K-Means)을 사용하여, 실시간으로 들어오는 미지의 주식을 분석하는 예측(Prediction) 엔진을 구현해보겠습니다.
AI의 작동 흐름: 뇌와 번역기
실제 서비스에서 이 엔진이 작동하는 흐름은 다음과 같습니다.
- 입력: 사용자가 '삼성전자'를 포트폴리오에 추가합니다.
- 데이터 수집: API를 통해 삼성전자의 최신 재무 지표(PER, PBR 등)를 가져옵니다.
- 전처리(번역): 이 지표를 학습 때와 똑같은 기준(StandardScaler)으로 스케일링합니다.
- AI 예측: 저장해둔 AI 모델(kmeans_model.pkl)에 데이터를 넣고 질문합니다.
- 결과: AI가 [5]라는 답을 줍니다.
- 태그 변환: 숫자 5를 [초대형 우량주]라는 태그로 변환하여 보여줍니다.
이 과정을 위해 가장 먼저 해야 할 일이 있습니다. 바로 전처리 과정에서 놓쳤던 번역기(Scaler)를 챙기는 것입니다.
문제 : 번역기(Scaler)를 저장하지 않았다
우리의 AI 모델(kmeans_model.pkl)은 학습된 뇌입니다. 하지만 이 뇌는 스케일링 된 숫자만 이해할 수 있습니다.
우리가 500개 종목을 학습시킬 때 StandardScaler라는 도구를 사용해 원본 데이터를 AI가 이해하기 쉬운 숫자로 바꿨습니다. 그렇다면 새로운 삼성전자 데이터가 들어왔을 때도 똑같은 도구로 바꿔줘야 합니다.
그런데 이 도구를 저장하지 않았습니다.
해결 : 번역기 생성
preprocess.py로 돌아가서 코드를 수정합니다.
# ... (기존 코드 하단)
# [추가된 부분]
# AI가 새로운 데이터를 이해할 수 있도록 '번역기(Scaler)'를 저장합니다.
import joblib
joblib.dump(scaler, 'scaler.pkl')
print("3. scaler.pkl (AI 예측용 번역기) 파일이 생성되었습니다.")
이제 이 코드를 실행하면 scaler.pkl 파일이 생성됩니다. 이것으로 AI에게 말을 걸 수 있는 번역기가 준비되었습니다.
실시간 예측 엔진 구현
이제 AI의 뇌(Model)와 번역기(Scaler)가 모두 준비되었습니다.
이 두 파일을 로드해서, 들어오는 데이터를 실시간으로 분석하는 예측 함수를 만들어 보겠습니다.
이것이 바로 우리가 원하는 500개 목록과 상관없이 작동하는 AI의 핵심 엔진입니다.
import joblib
# 1. 모델과 번역기 로드
model = joblib.load('kmeans_model.pkl')
scaler = joblib.load('scaler.pkl')
def predict_style(stock_df):
# 1. 번역기로 신규 데이터를 번역 (스케일링)
# 주의: fit_transform이 아니라 transform을 써야 합니다. (기준은 변하면 안 되니까요)
scaled_data = scaler.transform(stock_df)
# 2. AI에게 예측 명령
predicted_group = model.predict(scaled_data)
return predicted_group[0] # 예: 5
원리는 간단합니다. 저장된 기준(Scaler)대로 데이터를 자르고, 저장된 뇌(Model)에게 판단을 맡기는 것입니다.
실전투입 : 세상의 모든 주식을 분석하다
이제 모든 준비가 끝났습니다. 학습 데이터에 없었던 삼성전자와 DB하이텍을 포트폴리오에 담고, AI에게 분석을 요청해 보겠습니다.
과연 AI는 이 주식들을 어떻게 평가하고, 어떤 페르소나와 매칭시켜 줄까요?
import pandas as pd
import numpy as np
import joblib
import persona_definitions as pd_data
from numpy.linalg import norm
# ----------------------------------------------------
# 1. 가상의 사용자 포트폴리오 (학습에 없던 주식 포함)
# ----------------------------------------------------
# 시뮬레이션: 삼성전자(50%) + DB하이텍(50%)
user_portfolio_data = {
'단축코드': ['005930', '000990'],
'투자금액': [1000000, 1000000]
}
user_df = pd.DataFrame(user_portfolio_data)
# ... (중략: 모델 로드 및 예측 로직) ...
# ----------------------------------------------------
# 2. 실행 결과 출력
# ----------------------------------------------------
if __name__ == "__main__":
user_vector, merged_details = get_style_vector(user_df, stock_db, scaler, model)
print("🚀 사용자 포트폴리오 종합 분석 리포트")
# 보유 종목 상세 분석 결과
for index, row in merged_details.iterrows():
print(f"📊 {row['한글명']}: {row['final_style_tag']}")
# 페르소나 매칭 결과
match_results = calculate_persona_match(user_vector)
# ... (출력 로직)
실행 결과: AI의 판단
코드를 실행하면 다음과 같은 놀라운 결과가 나옵니다.
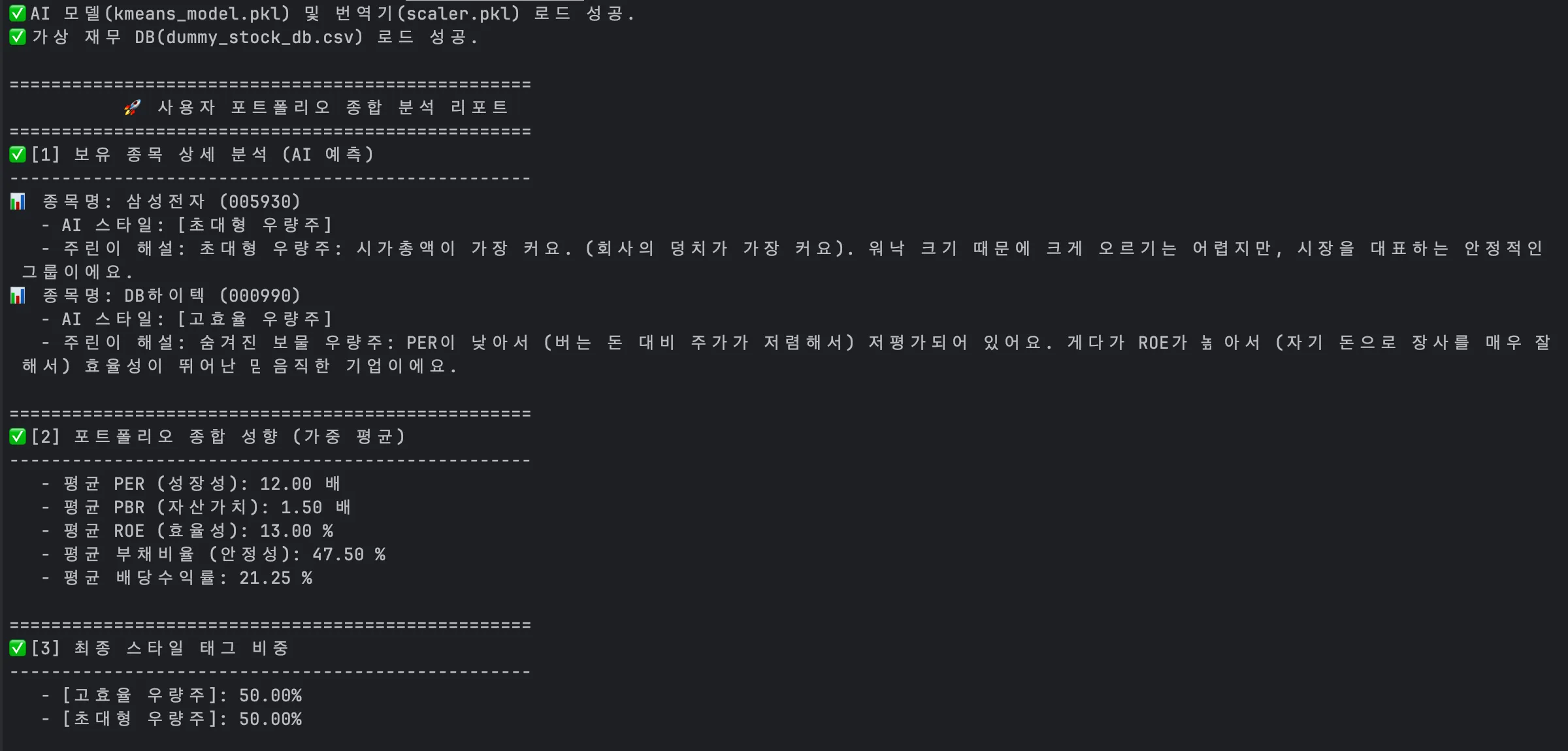

이 성공이 의미하는 것
- 500개 목록의 한계 극복 삼성전자는 학습 데이터인 stockit_final_tagged_data.csv에 없었습니다. 하지만 AI는 스스로 재무 지표를 분석하여 삼성전자를 5번 그룹([초대형 우량주])으로 정확하게 분류했습니다.
- 페르소나의 확장 데이터베이스에 없는 주식들을 섞어서 샀음에도 불구하고, 시스템은 사용자의 투자 성향을 존 보글과 워렌 버핏의 조합으로 완벽하게 해석해냈습니다.
이제 주식쌤은 단순히 과거 데이터를 조회하는 엑셀 파일이 아닙니다.
실시간으로 변하는 시장의 어떤 주식이 들어와도 0.1초 만에 성향을 분석해내는 살아있는 실시간 예측 엔진이 되었습니다.
마치며 : 죽은 데이터에서 살아있는 엔진으로
지금까지 AI 주식 분석 시스템의 핵심 엔진을 개발하는 과정을 다뤘습니다.
- 데이터를 수집하고 (전처리)
- 끼리끼리 묶어서 (K-Means 클러스터링)
- 이름을 붙여주고 (스타일 태깅)
- 캐릭터를 입히고 (페르소나 매칭)
- 미지의 주식까지 분석하는 (실시간 예측)
이 과정을 통해 우리는 숫자로 된 주식 시장을 사람의 언어로 통역하는 통역기를 만들었습니다.
이제 남은 것은 이 강력한 엔진을 예쁜 자동차(웹 서비스)에 얹는 일뿐입니다.

다음 글에서는 이 파이썬 엔진을 실제 웹 서비스(FastAPI)와 연동하여 사용자가 직접 체험할 수 있는 서비스로 만드는 "파이썬 AI, 웹 서버가 되다" 백엔드 개발 과정을 다뤄보겠습니다.
'모의투자' 카테고리의 다른 글
| ~서버가 로그 없이 죽었다 : 쿠버네티스를 디버거로 쓴 사연~ 스톡잇! 개발기 #9 (1) | 2025.12.26 |
|---|---|
| ~파이썬 AI, 웹 서버가 되다 : MSA와 FastAPI 아키텍처에 대한 고찰~ 스톡잇! 개발기 #8 (0) | 2025.12.26 |
| ~투자 성향을 캐릭터로 만들다: 페르소나 매칭 설계~ 스톡잇! 개발기 #6 (0) | 2025.12.26 |
| ~숫자를 언어로 번역하다 : 태깅~ 스톡잇! 개발기 #5 (1) | 2025.12.26 |
| ~숫자만 보고 주식을 나누다: K-means 클러스터링 과정~ 스톡잇! 개발기 #4 (0) | 2025.12.25 |